
How to build scalable message processing system with RabbitMQ and millions of Goroutines
In this article, we cover the advantages of using RabbitMQ and Goroutines, setup instructions, system design, implementation, benchmarking, scaling, and real-world use cases.


How to build scalable message processing system with RabbitMQ and millions of Goroutines
Scalable and efficient message processing system is a key component in many applications and systems. From marketing operations to devops to customer facing application features there are several use-cases where scalable message processing system is required.
In this article, we will explore how to use RabbitMQ, a robust message broker, and Goroutines, a lightweight concurrency mechanism in Go programming language, to build scalable message processing systems that can handle millions of concurrent operations with ease.
Why RabbitMQ and Goroutines?
Before we get into the implementation details, let's take a moment to understand why RabbitMQ and Goroutines are a match made in heaven for scalable message processing.
RabbitMQ is a widely adopted open-source message broker that supports multiple messaging protocols, including AMQP, MQTT, and STOMP. It acts as a middleman between message producers and consumers, enabling reliable message delivery, routing, and queuing. RabbitMQ's key features include:
1. High Scalability: RabbitMQ can handle a massive number of concurrent connections and messages, making it suitable for large-scale systems.
2. Flexibility: With support for various messaging patterns like publish-subscribe, point-to-point, and request-reply, RabbitMQ caters to diverse messaging needs.
3. Reliability: RabbitMQ ensures message persistence and provides mechanisms for message acknowledgments and dead-letter exchanges to handle failures gracefully.
On the other hand, Goroutines are a lightweight thread-like abstraction provided by the Go programming language. They allow you to write concurrent programs with ease, thanks to Go's built-in support for concurrency. Goroutines are incredibly efficient, with a minimal memory footprint, and can scale to millions of concurrent operations on a single machine. Go's channels provide a convenient way to communicate and synchronize between Goroutines, making it simpler to build concurrent systems.
By leveraging the power of RabbitMQ for reliable message brokering and Goroutines for efficient concurrent processing, we can build a highly scalable message processing system that can handle massive workloads.
Setting Up the Environment:
To get started, you'll need to have Go and RabbitMQ installed on your development machine. You can download and install Go from the official website (https://golang.org) and follow the installation instructions specific to your operating system. For RabbitMQ, you can either install it locally or use a managed RabbitMQ service like CloudAMQP
Once you have Go and RabbitMQ set up, create a new Go project and install the necessary dependencies. We'll be using the "github.com/streadway/amqp" package to interact with RabbitMQ. You can install it by running the following command:
Designing the Message Processing System:
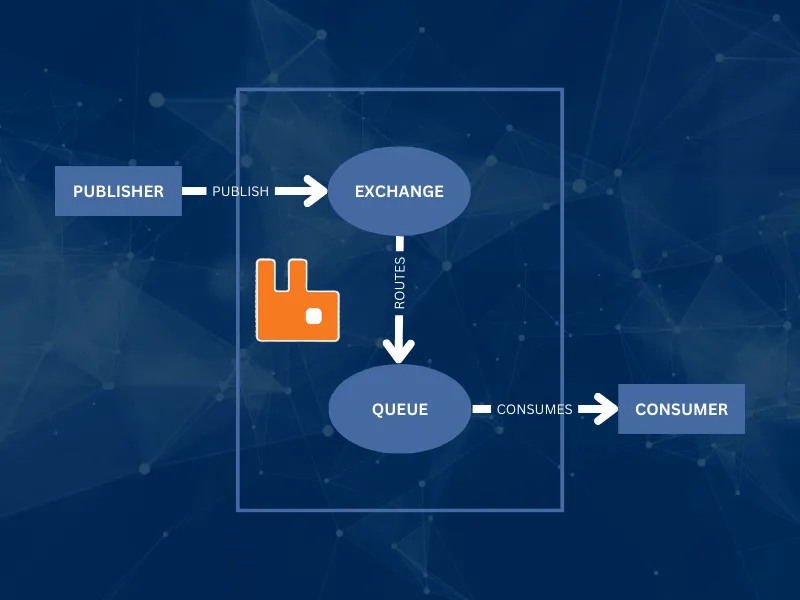
Now, let's dive into the design of our scalable message processing system. The system will consist of the following components:
1. Message Producer: A Go program that generates messages and publishes them to a RabbitMQ exchange.
2. RabbitMQ Exchange and Queues: An exchange in RabbitMQ that receives messages from the producer and routes them to appropriate queues based on binding rules.
3. Message Consumer: A Go program that spawns multiple Goroutines, each acting as a consumer to process messages from the RabbitMQ queues concurrently.
Here's a high-level diagram illustrating the system architecture:
Implementing the Message Producer:
Let's start by implementing the message producer. Here's a sample code snippet that demonstrates how to publish messages to a RabbitMQ exchange:
In this example, we establish a connection to RabbitMQ using the "amqp.Dial" function, specifying the URL to the RabbitMQ server. We then create a channel using "conn.Channel()" to interact with RabbitMQ.
Next, we declare an exchange named "logs" of type "fanout". A fanout exchange broadcasts all the messages it receives to all the queues bound to it.
Inside a loop, we publish 1 million messages to the "logs" exchange. Each message is a simple string containing a message number. We set the "ContentType" to "text/plain" and convert the message body to a byte slice before publishing.
The "failOnError" function is a helper function that logs and terminates the program if an error occurs.
Implementing the Message Consumer:
Now, let's implement the message consumer that will process the messages from the RabbitMQ queues. Here's a sample code snippet:
In the message consumer, we establish a connection to RabbitMQ and create a channel, similar to the message producer.
We declare the same "logs" exchange to ensure that the consumer is listening to the same exchange as the producer.
Next, we declare a queue with a unique name (generated by RabbitMQ) using "ch.QueueDeclare". We set the "Exclusive" flag to "true" to ensure that the queue is deleted when the consumer disconnects.
We bind the declared queue to the "logs" exchange using "ch.QueueBind". This ensures that the messages published to the "logs" exchange are routed to the bound queue.
We start consuming messages from the queue using "ch.Consume". We set "Auto-ack" to "true" to automatically acknowledge the messages once they are received.
Here's the exciting part: we spawn 1 million Goroutines using a "for" loop. Each Goroutine acts as a consumer and processes messages from the "msgs" channel concurrently. Inside each Goroutine, we range over the "msgs" channel and log each received message. You can add your custom message processing logic here.
Finally, we create a "forever" channel and block the main Goroutine to keep the consumer running indefinitely. You can gracefully stop the consumer by pressing CTRL+C.
Benchmarking and Scaling:
Let's put our message processing system to the test and see how it performs under heavy load. We'll use the "pprof" package in Go to profile the system and identify any performance bottlenecks.
First, modify the message consumer code to enable profiling:
We import the "net/http/pprof" package and start an HTTP server on "localhost:6060" to serve the profiling data.
Now, run the message producer to publish 1 million messages to RabbitMQ, and then run the message consumer to process those messages.
While the consumer is running, open a new terminal and use the "go tool pprof" command to profile the system:
This command will collect profiling data for 30 seconds (default duration) and open an interactive pprof shell. Inside the shell, you can use various commands to analyze the performance:
- "top": Displays the top functions by CPU usage.
- "list": Shows the source code and CPU usage of a specific function.
- "web": Opens a web-based visualization of the profiling data.
By analyzing the profiling data, you can identify performance bottlenecks and optimize your code accordingly.
To scale the system horizontally, you can run multiple instances of the message consumer on different machines. RabbitMQ will automatically distribute the messages among the available consumers, allowing for parallel processing.
You can also scale RabbitMQ itself by running it in a clustered configuration. RabbitMQ supports clustering, where multiple nodes form a cluster and share the message queues. This provides high availability and allows for distributing the message processing load across multiple RabbitMQ nodes.
Real-World Use Cases:
Scalable message processing systems like the one we've built have numerous real-world applications. Here are a few examples:
1. Event-Driven Architectures: In event-driven architectures, various services communicate through events. RabbitMQ can act as the event broker, allowing services to publish events and consume them asynchronously. This enables loose coupling and scalability.
2. Log Aggregation and Processing: In large-scale systems, collecting and processing logs from multiple sources can be challenging. By using RabbitMQ as a centralized log aggregator, you can publish log messages from different services to RabbitMQ and have dedicated log processing consumers that analyze and store the logs.
3. Real-Time Data Processing: Applications that require real-time data processing, such as fraud detection systems or real-time analytics, can benefit from a scalable message processing system. RabbitMQ can handle high-throughput data ingestion, and Goroutines can process the data concurrently, enabling real-time insights.
4. Asynchronous Task Execution: In scenarios where you have resource-intensive tasks that can be executed asynchronously, such as image processing or video transcoding, you can use RabbitMQ to decouple the task submission from the actual execution. Producers can submit tasks to RabbitMQ, and consumers can process them in the background, allowing for efficient resource utilization.
Conclusion:
Building a scalable message processing system with RabbitMQ and millions of Goroutines is a powerful approach to handle high-volume, real-time data processing needs. By leveraging the reliability and flexibility of RabbitMQ and the concurrency capabilities of Goroutines, you can build systems that can scale horizontally and handle massive workloads.
Remember to profile and optimize your system using tools like pprof to ensure optimal performance. Continuously monitor and fine-tune your system based on the specific requirements of your use case.
With the right architecture and implementation, you can unlock the full potential of RabbitMQ and Goroutines to build robust, scalable, and efficient message processing systems that power modern applications.
Happy coding and scaling!


