
Getting started with Microservices and Docker
Although many web apps have had success using the monolithic architectural approach, it comes with its limitations. Mainly its reliability, as a single bug in any module can bring the entire application down; another is that these applications are developed using a single stack which can limit the availability of “the right tool for the job.” This is where “microservices” come into the picture and this is where I’ve started learning it. But, to understand microservices, we need to understand containers.


What exactly is ‘container’ and how does it differ from ‘VMs’:
Virtualization uses software to create an abstraction layer over computer hardware that allows the hardware elements of a single computer— processors, memory, storage and more to be divided into multiple virtual computers, commonly called virtual machines (VMs). Each VM runs its own operating system (OS) and behaves like an independent computer, even though it is running on just a portion of the actual underlying computer hardware. This allows multiple applications to run on the same physical machine in a fully isolated and portable way. Although both containers and VMs provide virtualization, they address different challenges.
Simply put, a virtual machine is an emulation of a physical computer. VMs enable teams to run what appear to be multiple machines, with multiple operating systems, on a single computer. VMs interact with physical computers by using lightweight software layers called hypervisors.
For a complete overview of VMs, see "What is a Virtual Machine?
In traditional virtualization, a hypervisor (A hypervisor is the software layer that coordinates VMs.) virtualizes physical hardware. The result is that each virtual machine contains a guest OS, a virtual copy of the hardware that the OS requires to run an application and its associated libraries and dependencies. Due to this, VMs tend to have large size, use a lot of system memory and this adds a lot of load and makes spinning up your VMs a very slow process.
Containers use a form of operating system (OS) virtualization instead of virtualizing the underlying hardware. Put simply, they leverage features of the host operating system to isolate processes and control the processes’ access to CPUs, memory and desk space.
So each individual container contains only the application and its libraries and dependencies. They share an underlying OS kernel, only running the application and the things it depends on, like software libraries and environment variables. This makes containers smaller and faster to deploy.
For a deep dive into containers and containerization, check out “Containers: A Complete Guide” and “Containerization: A Complete Guide.”
There are lots of container options to choose from nowadays. One popular container option is Docker, and I’ll use it as an example of a container engine in this article.
‘Microservice’, in a picture now:
In one sentence, Microservices is an architecture that focuses on creating a collection of focused and small services which, on execution, develops a complete application. This way we successfully eliminate both major limitations of the Monolithic approach.
Large applications are broken into small Services which are then containerized and deployed together as a single application. Microservices are meant to do one thing only, without requiring a lot of context that is provided to them. That means you can assign each microservice a particular task. You should be able to shut them down and spin them easily, without disrupting other work streams or actions.
This cannot be done in a monolithic application. You can’t run the same application that requires five or six different libraries that expect different versions. Microservices can solve multiple dependencies in a complex application, very easily. Orchestrate everything in a way that you’re running multiple runtimes and libraries on one machine. They are all independently updated and upgraded components and you wouldn’t have to change the overall application, just the tasks/items that you want. Following diagram gives a basic overview of both architectures.
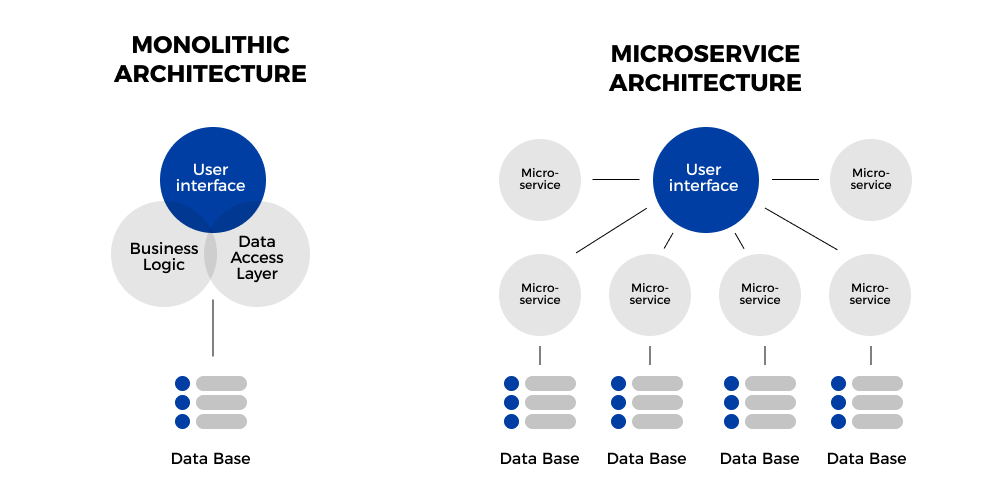
How Microservices ‘communicate’ with each other
Microservices have many advantages but it comes with a Challenge which is how these services must interact and communicate with each other. Communication between microservices must be efficient and robust. With lots of small services interacting to complete a single business activity, this can be a challenge. There are two basic messaging patterns that microservices can use to communicate with other microservices.
- Synchronous communication. In this pattern, a service calls an API that another service exposes, using a protocol such as HTTP or gRPC. This option is asynchronous a synchronous messaging pattern because the caller waits for a response from the receiver.
- Asynchronous message passing. In this pattern, a service sends a message without waiting for a response, and one or more services process the message asynchronously.
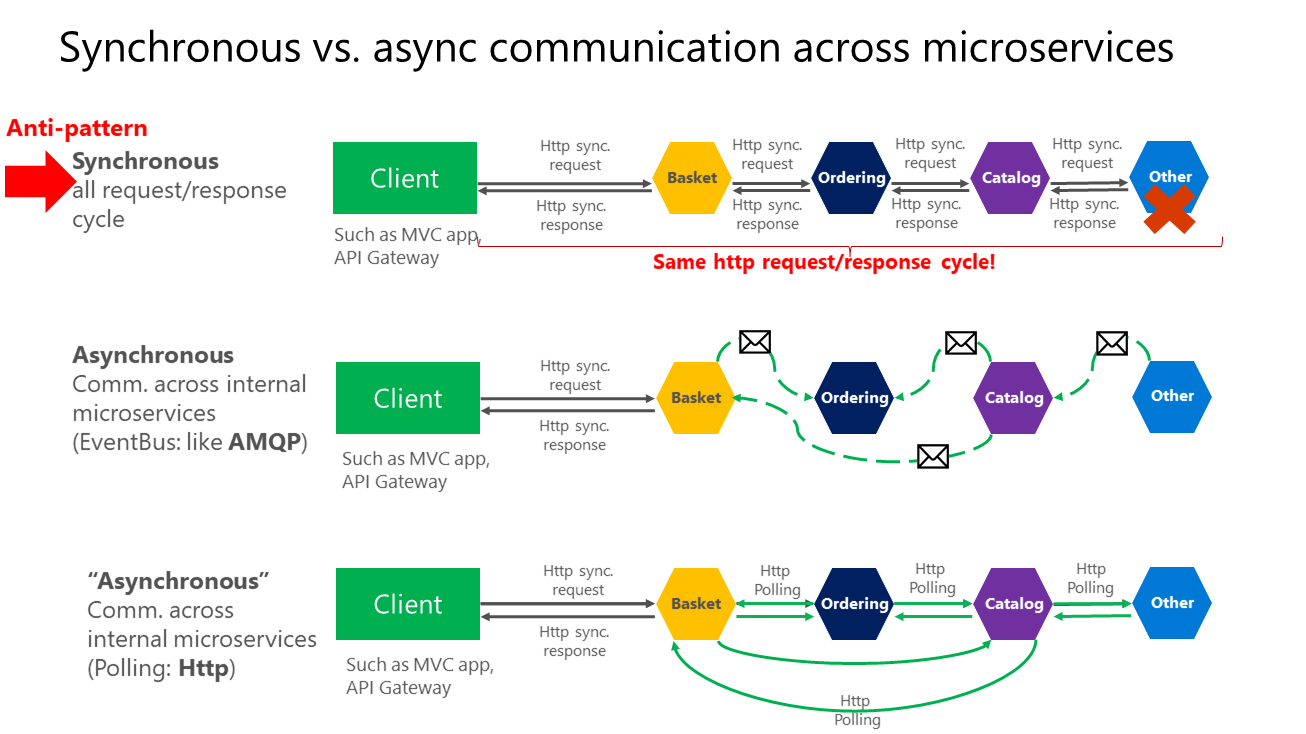
As shown in the above diagram, in synchronous communication a "chain" of requests is created between microservices while serving the client request. This is an anti-pattern. In asynchronous communication microservices use asynchronous messages or http polling to communicate with other microservices, but the client request is served right away
Read These articles for better understanding of Interservice communication and communication in microservices.
Though we can have synchronous request/response calls when the requester expects immediate response, integration patterns based on events and asynchronous messaging provide maximum scalability and resiliency. In order to build scalable architectures, we need event-driven and asynchronous integration between microservices. In asynchronous event-driven communication, one microservice publishes events to an event bus and many microservices can subscribe to it, to get notified and act on it. Your implementation will determine what protocol to use for event-driven, message-based communications. Most popular protocol for this is AMQP (Advanced Message Queuing Protocol) So with using AMQP protocols, the client sends the message using message broker systems like Kafka and RabbitMQ queue. The message producer usually does not wait for a response. This message consumes from the subscriber systems in async way, and no one is waiting for a response suddenly. For more details about AMQP, dive into this documentation.
Asynchronous communication via ‘RabbitMQ’ between microservices:
For my small project, I used rabbitmq which is a message broker for exchanging data. Rabbitmq has really good documentation and it's quite simple to use with all programming platforms. The 2 terms most commonly used in rabbitmq are producer (who sends the message) and customer (who consumes the message). The core idea in the messaging model in RabbitMQ is that the producer never sends any messages directly to a queue. Actually, quite often the producer doesn’t even know if a message will be delivered to any queue at all.
Instead, the producer can only send messages to an exchange. An exchange is a very simple thing. On one side it receives messages from producers and the other side it pushes them to queues.
The exchange must know exactly what to do with a message it receives. Should it be appended to a particular queue? Should it be appended to many queues? Or should it get discarded. The rules for that are defined by the exchange type (direct, topic, headers and fanout). For more details on types of exchanges, take a look at this article.
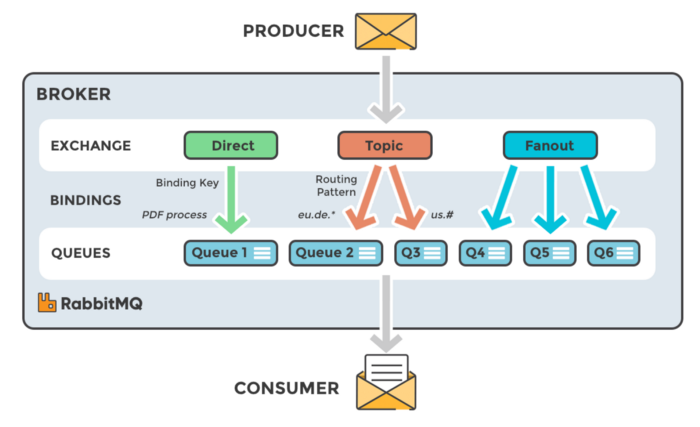
The super simplified overview:
- Publishers send messages to exchanges
- Exchanges route messages to queues and other exchanges
- RabbitMQ sends acknowledgements to publishers on message receipt
- Consumers maintain persistent TCP connections with RabbitMQ and declare which queue(s) they consume
- RabbitMQ pushes messages to consumers
- Consumers send acknowledgements of success/failure
- Messages are removed from queues once consumed successfully
Take a look at these tutorials on how to implement rabbitmq for practical knowledge.
Lets tie all of this up and see Microservices in action.
As I mentioned earlier, I used rabbitmq to establish my asynchronous communication. For python we need Pika to access rabbitmq server. Hence I recommend installing rabbitmq and pika first. My 2 microservices were an email sender and a logger who just logs the time and details of the email. Both these services were (consumer) consuming from my main flask API (producer) which just declared an end point to get the recipient address, subject and body of the email and then send them to both my microservices.
Here is how I used rabbitmq for my Flaskapp.py
connection = pika.BlockingConnection(
pika.ConnectionParameters(host='localhost'))
channel = connection.channel()
#Declaring exchange with fanout exchange type
channel.exchange_declare(exchange='logs', exchange_type='fanout')
After importing pika we need to initialize the connection to the host and establish a channel. I have declared and used fanout exchange type as it just broadcasts the messages to all the consumers subscribed to the queue. However in a practical world we need end to end exchanges but for my small project this exchange type just did the trick.
Here is how the message is broadcasted through the endpoint /send of our flaskapp.
Data=[]
@app.route('/send',methods= ['POST'])
def send():
request_data = request.get_json()
email = {
'toaddr': request_data['toaddr'],
'subject' : request_data['subject'],
'body': request_data['body'],
}
Data.append(email)
#Sending the data to Queue.
#dumps - converts python object into a serialized JSON object
channel.basic_publish(exchange='logs', routing_key='', body = json.dumps(Data))
return jsonify(Data)
After this we need to just set-up our consumers which are logger and emailer in our scenario to consume these messages from the queue.
Here is a code snippet to connect logger.py to rabbitmq server and how messages are consumed.
def main():
connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost'))
channel = connection.channel()
#Declaring exchange
#it's important to declare same exchange as the producer
#here we have 'logs' and type as fanout
channel.exchange_declare(exchange='logs', exchange_type='fanout')
result = channel.queue_declare(queue='', exclusive=True)
queue_name = result.method.queue
channel.queue_bind(exchange='logs', queue=queue_name)
def callback(ch, method, properties, body):
#loads - Deserializes a JSON object to a standard python object
email = json.loads(body)
#passing this to our custom logger.
logger.info(email)
print("record logged")
channel.basic_consume(queue=queue_name, on_message_callback=callback,
auto_ack=True)
print(' [*] Waiting for messages. To exit press CTRL+C')
channel.start_consuming()
I've implemented a custom logger with formatting and file handling. Don’t worry, I'll mention the link to the entire code at the end. What's happening over here is that we receive the message i.e. email details within the body parameter of our callback function. Then we can use this to perform any desired task.
Similarly emailer.py is also implemented with the same logic. This way we can establish asynchronous communication between different services.
How ‘docker’ helps building microservices
Microservices fit nicely with the Docker paradigm. Docker allows you to build those microservices and helps you move towards the microservices architecture. It was my first time using Docker and I was amazed by its minimal syntax and simplicity. With Docker, we get a single object that can reliably run anywhere. Docker's simple and straightforward syntax gives us full control. I have assumed you installed docker on your host machine.
We can check the version on Linux using the following command.
ubantu@coditationsys:~$ docker -v
Docker version 20.10.7, build 20.10.7-0ubuntu5~18.04.3
While using docker there are 2 terminologies that one should have a clear understanding of, which are images and containers. They both can be compared to the difference between a class and an object. As an object is the runtime instance of a class. Similarly, a container is the runtime instance of an image. But what is an image? A Docker image contains application code, libraries, tools, dependencies and other files needed to make an application run. When a user runs an image, it can become one or many instances of a container. Container’s a virtualized run-time environment where applications are isolated from the underlying system. Docker images have multiple layers, each one originates from the previous layer but is different from it. The layers speed up Docker builds while increasing reusability and decreasing disk use. Image layers are also read-only files. Once a container is created, a writable layer is added on top of the unchangeable images, allowing a user to make changes. We can create custom images that are built on top of a base image using a docker file. That's what we are going to do. We can also declare environmental variables, also ports which are used for communication in this docker file. After running a simple docker build command our custom image is created. These images can be stored in local repositories or on the Docker hub.
There are many official images of applications available on docker hub, we can pull and run anyone on our host machines like this.
ubantu@coditationsys:~$ docker pull mysql:5.7
Docker demon will pull and run mysql image specifically of version 5.7 and run it inside a container.
Similarly start rabbitmq inside a container using
docker run -d --hostname localhost --name myrabbit rabbitmq:3
To check if its running - $ docker ps output -
CONTAINER ID IMAGE COMMAND CREATED STATUS
6d95830a43d9 rabbitmq:3 "docker-entrypoint" 6 minutes4369/tcp, 5671-5672/tcp,
PORTS NAMES
25672/tcp myrabbit
Now in order to create a custom image of our application we have to create a Dockerfile. Here’s how i created one for my emailer.py
FROM python:alpine3.7
WORKDIR /app
RUN pip3 install pika
COPY . /app
ENTRYPOINT [ "python3" ]
CMD [ "emailer.py" ]
All images are created on top of a base image. Here we have used python image with alpine 3.7 version which is a lightweight image based on alpine linux. RUN command executes any Linux command. Entrypoint and cmd combine to specify which file should be executed and what environment our container should have.
To build an image from this file we use the following command.
ubantu@coditationsys:~/Emailer$ docker build -t myemailer .
-t flag is used to give a name tag to the image and lastly we mention the path but as I'm inside the current directory i used '.'. We can check if our image has been created using :$ docker images. This lists out all the images present on the host.
In order to create a container from this we use following command.
ubantu@coditationsys:~/Emailer$ docker run -it -d -name emailerapp myemailer
Name flag is used to give the desired name to the container and lastly we mention the image name that we want to run inside the container. Vola! We have successfully created our first custom image and started it inside a container.
As mentioned earlier we can check running containers by $ docker ps - you can see that our emailerapp is running. To stop any container use $ docker stop <container id>. We can start a stopped container by using $ docker start <container id>. Inorder to check all the containers created you have to use
$ docker ps -a. This lists all the containers created. To delete an existing container use $ docker rm <container id>.
Similarly we can run our flask API and emailer inside a container using the above steps.
But wait, you got an error stating the following right? Let's take a look at.
raise self._reap_last_connection_workflow_error(error)
pika.exceptions.AMQPConnectionError
It says that our microservices are not able to connect to our rabbitmq server. While we were running our services locally we established a connection by using host = localhost but once we are running our services from the container this won't work as our rabbitmq is not running on our localhost ip.
This can be solved using 2 ways. The first is to simply inspect the running rabbitmq server by using
$ docker inspect <rabbitmq’s container id>. This gives an output of the status of rabbitmq and here we can get the ip address on which our rabbitmq is running.
Then simply change the host as follows.
connection=pika.BlockingConnection(pika.ConnectionParameters(host='172.17.0.2'))
My rabbitmq is running on 172.17.0.2. You can check yours and edit the host accordingly.
Docker Networks - Another approach and this is the important one is to declare a network. Docker takes care of the networking aspects so that the containers can communicate with other containers and also with the Docker Host.
We can create our own network using
$ docker network create <name>
Containers can only communicate when they are all running in the same network. Containers on the default bridge network can only access each other by IP addresses as we did on our first approach. On a user-defined bridge network, containers can resolve each other by name or alias. Take a deep look into Network and bridge as this is an important topic.
As we now know that we can run multiple containers on a single host at any given time. Up until now we have been creating separate docker files for each service and then containerizing them individually. But as our application can have multiple services and making a docker file for each can be a long and tedious task. So is there a simplified way to solve this?
Bridging containers and load-balancing using docker-compose:
Docker-compose tool is used to build and run multiple images through a single YAML file. All services are declared in a single file and by just running command docker-compose up - our images are built and started inside a container. Docker-compose automatically creates a user-defined network for us as well. Also all ports, environmental variables are declared in a single file. Take a look at this article for more details on how to create a docker compose file.
Data restoration is a key, and creation of volume is important:
When a container is stopped or goes down, all the data and logs of that container are lost as data is not stored outside the container, it's stored in a virtual files system. After we restart our containers our virtual files system starts fresh with all previous records lost. Docker solves this problem with volume. When we want to save data in our local machine. That's when we need volumes. So what are volumes? On our host we have a physical host file system. So how volumes work is that the folder in the physical host file system is mounted into the virtual file system of docker. So what happens is that when any data is written in the Virtual file system it gets auto replicated in the host file system directory.
Lets mount a local path for our logger service as our data needs to replicate on the host.
ubantu@coditationsys:$ docker run -d -name loggerapp \
-v <host_machine_directy>:<container_directory> <imagename>
This will mount the host directory to the containers directory. This way data is auto replicated in the mentioned host directory and our logs will be auto replicated on our host path. Also worth noting that persistence goes both ways with this approach. Any changes made to the files from within the container are reflected back onto the host. Any changes from the host are also reflected inside the container.
Conclusion
Congratulations, you successfully learned about Microservices, Docker and how to break down your monolithic apps. We learnt that Microservices architecture is a distributed design approach intended to overcome the limitations of traditional monolithic architectures. Also we found out how microservices modernize our app development process and Docker helps with all this.
Here a Github link to the entire project - https://github.com/Codewithgk/Microservices-with-docker-and-rabbitmq
Reference
https://www.divante.com/blog/monolithic-architecture-vs-microservices
https://medium.com/@aamermail/asynchronous-communication-in-microservices-14d301b9016
https://www.youtube.com/watch?v=3c-iBn73dDE
https://www.youtube.com/watch?v=Qw9zlE3t8Ko
https://www.cloudamqp.com/blog/part2-3-rabbitmq-for-beginners_example-and-sample-code-python.html




No Hype. Just Systems That Deliver Real Outcomes at Scale.


A1004, Amar Business Zone, Baner, Pune, Maharashtra – 411045





